
Lượng Tử Hóa Embedding: Chìa Khóa AI Di Động Nhẹ Hơn
Published on Tháng 1 20, 2026 by Admin

Tóm tắt: Các mô hình AI ngày càng lớn, gây khó khăn khi triển khai trên thiết bị di động. Bài viết này sẽ giới thiệu kỹ thuật lượng tử hóa token embedding, một giải pháp đột phá giúp giảm đáng kể kích thước và tăng tốc độ xử lý của mô hình AI, mở ra tương lai cho các ứng dụng di động thông minh và hiệu quả hơn.
Thách Thức Của AI Trên Thiết Bị Di Động
Trí tuệ nhân tạo (AI) đang thay đổi cách chúng ta tương tác với công nghệ. Tuy nhiên, việc đưa các mô hình AI mạnh mẽ lên thiết bị di động gặp rất nhiều rào cản. Các thiết bị này có tài nguyên phần cứng hạn chế, ví dụ như RAM, bộ nhớ lưu trữ và dung lượng pin.Hơn nữa, người dùng luôn mong đợi các ứng dụng phải nhanh và mượt mà. Một mô hình AI cồng kềnh có thể làm chậm ứng dụng, gây nóng máy và tiêu tốn pin. Đây chính là bài toán khó mà các nhà phát triển ứng dụng di động phải đối mặt. Do đó, việc tối ưu hóa mô hình là cực kỳ quan trọng, đặc biệt trong lĩnh vực điện toán biên (edge computing).Các mô hình ngôn ngữ lớn (LLM) là một ví dụ điển hình. Chúng có thể chứa hàng tỷ tham số, khiến kích thước tệp lên tới hàng gigabyte. Việc tích hợp một mô hình như vậy vào ứng dụng di động gần như là không thể nếu không có các biện pháp tối ưu hóa quyết liệt.
Token Embedding: “Từ Điển” Khổng Lồ Của AI
Để hiểu cách tối ưu hóa, đầu tiên chúng ta cần biết về token embedding. Hãy tưởng tượng nó như một cuốn từ điển khổng lồ. Cuốn từ điển này không định nghĩa từ ngữ, mà chuyển đổi mỗi từ (hoặc một phần của từ) thành một dãy số gọi là vector.Mô hình AI sử dụng các vector này để hiểu ý nghĩa và mối quan hệ giữa các từ. Tuy nhiên, lớp embedding này thường chiếm một phần đáng kể trong tổng kích thước của mô hình. Kích thước của nó được tính bằng công thức:Kích thước = (Số lượng từ trong từ vựng) x (Số chiều của vector)Ví dụ, một mô hình với 100.000 từ vựng và mỗi từ được biểu diễn bằng vector 1024 chiều sẽ có một ma trận embedding cực lớn. Nếu mỗi giá trị số là một số thực 32-bit (4 byte), lớp embedding này có thể chiếm hơn 400MB. Con số này là một gánh nặng thực sự cho bộ nhớ và dung lượng lưu trữ của điện thoại. Vì vậy, việc hiểu rõ chi phí của các mô hình học máy là bước đầu tiên để tối ưu chúng.
Giới Thiệu Về Lượng Tử Hóa (Quantization)
Lượng tử hóa là một kỹ thuật tối ưu hóa mạnh mẽ. Bạn có thể hình dung nó giống như việc nén một bức ảnh chất lượng cao. Thay vì lưu trữ ảnh dưới dạng tệp PNG lớn, bạn chuyển nó sang định dạng JPEG nhỏ hơn. Bức ảnh có thể mất đi một vài chi tiết nhỏ, nhưng kích thước tệp giảm đi đáng kể.
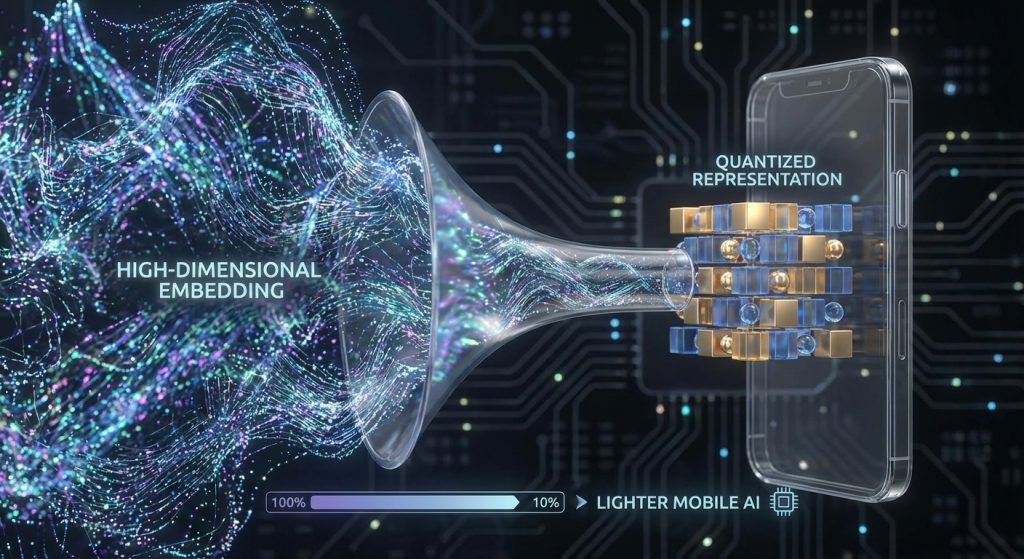
Trong AI, lượng tử hóa hoạt động tương tự. Kỹ thuật này chuyển đổi các con số trong mô hình từ định dạng có độ chính xác cao (như số thực 32-bit, FP32) sang định dạng có độ chính xác thấp hơn (như số nguyên 8-bit, INT8).
Lợi Ích Chính Của Lượng Tử Hóa
Việc giảm độ chính xác này mang lại nhiều lợi ích thiết thực:
- Giảm kích thước mô hình: Chuyển từ FP32 sang INT8 có thể giảm kích thước mô hình xuống 4 lần.
- Tăng tốc độ suy luận: Các phép toán trên số nguyên thường nhanh hơn nhiều so với số thực, đặc biệt trên các bộ xử lý di động.
- Tiết kiệm năng lượng: Ít tính toán phức tạp hơn đồng nghĩa với việc tiêu thụ ít pin hơn.
Những lợi ích này làm cho lượng tử hóa trở thành một công cụ không thể thiếu để chạy AI hiệu quả trên thiết bị di động.
Lượng Tử Hóa Token Embedding: Giải Pháp Tối Ưu
Trong khi nhiều người tập trung vào việc lượng tử hóa các lớp tính toán chính của mô hình, lớp token embedding thường bị bỏ qua. Tuy nhiên, như đã đề cập, đây lại là một trong những thành phần tốn nhiều dung lượng nhất. Do đó, áp dụng lượng tử hóa cho token embedding là một bước đi chiến lược.Quá trình này về cơ bản là chuyển đổi ma trận embedding từ các giá trị số thực sang số nguyên. Điều này giúp giảm kích thước bộ nhớ cần thiết để lưu trữ “cuốn từ điển” của mô hình. Kết quả là mô hình không chỉ nhỏ hơn mà còn tải nhanh hơn.Tất nhiên, có một sự đánh đổi nhỏ. Việc giảm độ chính xác có thể ảnh hưởng một chút đến hiệu suất của mô hình. Tuy nhiên, với các kỹ thuật hiện đại, sự sụt giảm này thường rất nhỏ và hoàn toàn có thể chấp nhận được để đổi lấy lợi ích về hiệu quả.
Các Kỹ Thuật Lượng Tử Hóa Phổ Biến
Có hai phương pháp chính để thực hiện lượng tử hóa:
1. Lượng Tử Hóa Sau Huấn Luyện (Post-Training Quantization – PTQ)
Đây là phương pháp đơn giản và nhanh nhất. Bạn chỉ cần lấy một mô hình đã được huấn luyện sẵn và áp dụng thuật toán lượng tử hóa lên nó. PTQ rất lý tưởng cho việc triển khai nhanh chóng mà không cần huấn luyện lại mô hình.
2. Lượng Tử Hóa Trong Khi Huấn Luyện (Quantization-Aware Training – QAT)
Phương pháp này phức tạp hơn. Nó mô phỏng quá trình lượng tử hóa ngay trong khi huấn luyện hoặc tinh chỉnh mô hình. Bằng cách này, mô hình “học” cách đối phó với độ chính xác thấp, giúp giảm thiểu sự sụt giảm về hiệu suất. QAT thường cho kết quả tốt hơn PTQ nhưng đòi hỏi nhiều công sức hơn.
Lợi Ích Thực Tế Cho Ứng Dụng Di Động
Việc áp dụng lượng tử hóa token embedding mang lại những cải tiến rõ rệt cho ứng dụng của bạn.
Giảm Kích Thước Ứng Dụng
Đây là lợi ích rõ ràng nhất. Một lớp embedding 400MB sau khi lượng tử hóa INT8 sẽ chỉ còn khoảng 100MB. Điều này giúp giảm kích thước tệp cài đặt (APK/IPA), khiến người dùng dễ dàng tải và cài đặt ứng dụng hơn.
Tăng Tốc Độ Phản Hồi
Mô hình nhỏ hơn sẽ tải vào bộ nhớ nhanh hơn. Điều này làm giảm thời gian khởi động của các tính năng AI. Ngoài ra, tốc độ suy luận nhanh hơn giúp ứng dụng phản hồi ngay lập tức, cải thiện đáng kể trải nghiệm người dùng.
Cho Phép AI Hoạt Động Offline
Với một mô hình nhỏ gọn, bạn có thể tích hợp nó trực tiếp vào ứng dụng. Điều này cho phép các tính năng AI hoạt động ngay cả khi không có kết nối internet. Người dùng có thể dịch ngôn ngữ, nhận dạng văn bản, hay tương tác với chatbot ở bất cứ đâu.
Câu Hỏi Thường Gặp (FAQ)
Lượng tử hóa có làm giảm nhiều độ chính xác của mô hình không?
Trong hầu hết các trường hợp, sự sụt giảm độ chính xác là rất nhỏ, thường chỉ khoảng 1-2%. Với kỹ thuật QAT, sự khác biệt này gần như không đáng kể. Đối với nhiều ứng dụng di động, lợi ích về tốc độ và kích thước hoàn toàn vượt trội so với sự sụt giảm nhỏ này.
Tôi nên chọn kỹ thuật lượng tử hóa nào, PTQ hay QAT?
Nếu bạn cần một giải pháp nhanh chóng và đơn giản, hãy bắt đầu với PTQ. Nó không yêu cầu dữ liệu huấn luyện và dễ thực hiện. Nếu bạn thấy độ chính xác giảm quá nhiều, hãy cân nhắc sử dụng QAT. QAT đòi hỏi nhiều công sức hơn nhưng thường cho kết quả tốt nhất.
Cần phần cứng đặc biệt để chạy mô hình đã lượng tử hóa không?
Không cần. Hầu hết các bộ xử lý di động hiện đại (CPU và GPU) đều được tối ưu hóa cho các phép toán số nguyên. Do đó, các mô hình được lượng tử hóa thường chạy rất hiệu quả trên các thiết bị có sẵn mà không yêu cầu phần cứng chuyên dụng.
Ngoài embedding, tôi có thể lượng tử hóa phần nào khác của mô hình?
Chắc chắn rồi. Bạn có thể và nên lượng tử hóa toàn bộ mô hình, bao gồm các lớp tích chập (convolutional), lớp kết nối đầy đủ (fully-connected) và các lớp chú ý (attention). Việc lượng tử hóa toàn diện sẽ mang lại hiệu quả tối ưu nhất.
Tóm lại, lượng tử hóa token embedding là một chiến lược quan trọng nhưng thường bị bỏ qua. Bằng cách giảm kích thước của thành phần này, các nhà phát triển có thể tạo ra các ứng dụng AI trên di động nhỏ hơn, nhanh hơn và tiết kiệm pin hơn, mang lại trải nghiệm vượt trội cho người dùng.
